When Should You Trust AI?
Trust Is Not Binary

Part of A Sceptic's Guide to AI.
"Should I trust this AI?" is the wrong question. It assumes trust is binary — you either trust a system or you do not. In practice, trust is a spectrum, and the right position on that spectrum depends on context.
A better question: How much trust is appropriate for this system, on this task, given what is at stake?
This page expands on the AI Trust Calculus introduced in the main guide. It provides a structured method for making trust decisions about AI systems — whether you are building them, deploying them, or simply using them at work.
Contents
The Trust Calculus
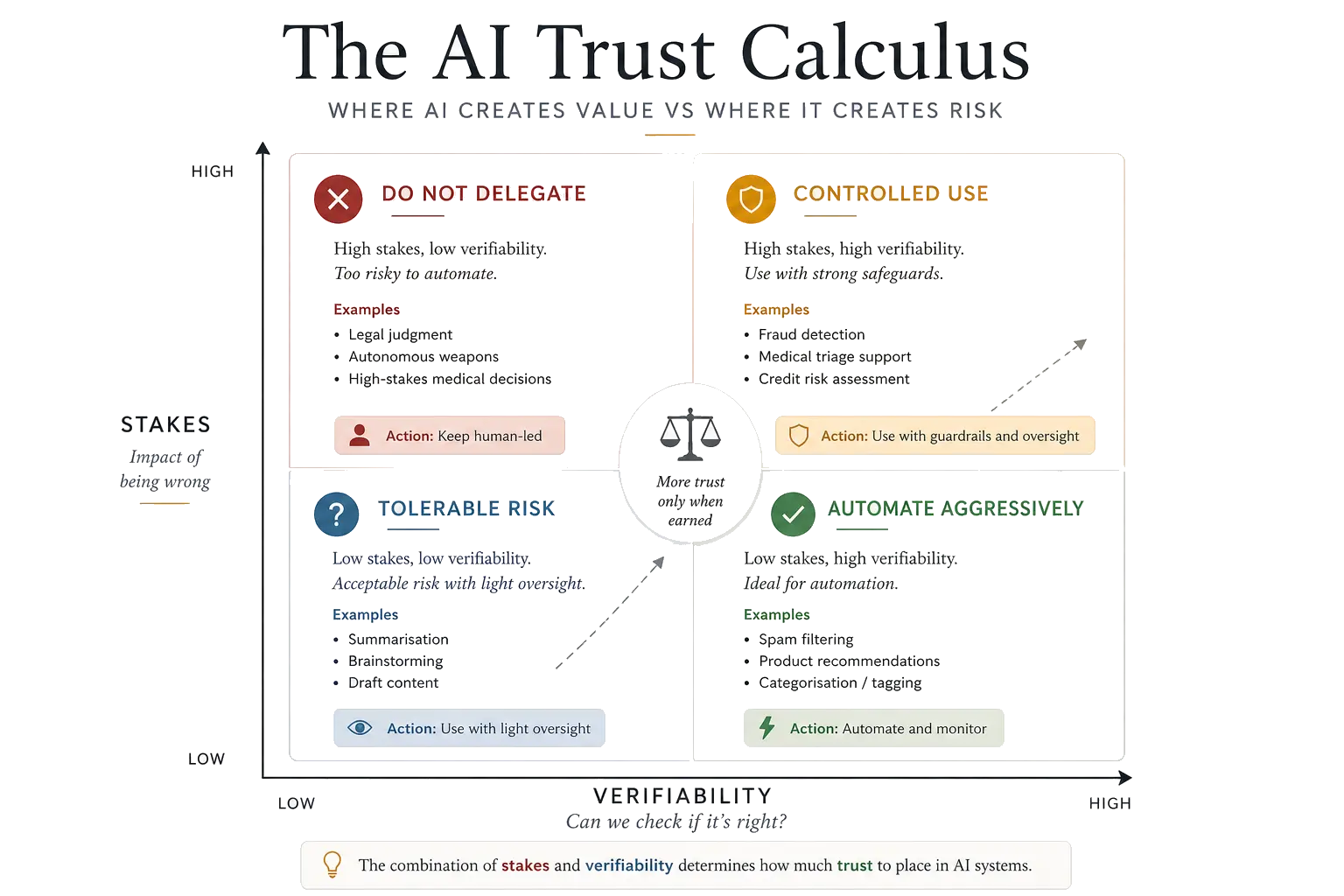
The basic Trust Calculus uses two dimensions: stakes and verifiability. For more nuanced decisions, two additional dimensions sharpen the analysis.
Stakes

What happens if the AI is wrong? This is the most important dimension because it determines the cost of misplaced trust.
- Low stakes: incorrect output is annoying but harmless. A miscategorised support ticket. A formatting error in an internal draft. A slightly wrong autocomplete suggestion.
- Medium stakes: incorrect output causes real but recoverable damage. A misleading data summary that delays a project. An inaccurate translation in a client email. A flawed first-pass analysis that wastes a team's time.
- High stakes: incorrect output causes serious, potentially irreversible harm. A flawed risk assessment in a financial system. A biased hiring decision. A wrong medical diagnosis. A mispriced contract based on a faulty forecast.
Verifiability

Can you check whether the output is correct? This determines whether trust needs to be blind or can be informed.
- Easy to verify: you can check the output quickly and reliably. Code that can be tested. A summary where you have read the source material. A translation into a language you speak.
- Hard to verify: checking the output requires significant expertise, time, or independent information. A legal analysis of an unfamiliar jurisdiction. A medical interpretation of complex imaging. A forecast of a market regime you have not seen before.
Reversibility

If you act on the AI's output and it turns out to be wrong, can you undo the damage?
- Reversible: you can correct course with minimal cost. Editing a draft. Adjusting a configuration. Re-running an analysis with different parameters.
- Irreversible: once acted upon, the decision cannot be undone or the cost of correction is severe. Publishing defamatory content. Denying someone a loan. Administering a medical treatment. Sending a military drone.
Reversibility interacts with stakes: a high-stakes, irreversible decision is the absolute worst place to extend unsupervised AI trust.
Scale

How many people or decisions does this affect?
- Individual: the output affects one person or one decision. Your own email draft. Your own code.
- Systematic: the output is applied across many cases automatically. A content moderation system applied to millions of posts. An automated lending decision affecting thousands of applicants. A hiring filter screening every CV that arrives.
Scale matters because it amplifies every other dimension. A small bias in a system that makes one decision is a rounding error. The same bias in a system that makes a million decisions is a systemic injustice.
Decision Table
Use this table to determine the appropriate trust posture for a given AI application. Find the row that best matches your situation.
| Scenario | Stakes | Verify | Reverse | Scale | Trust posture |
|---|---|---|---|---|---|
| Drafting an internal email | Low | Easy | Yes | Individual | Use freely, skim before sending |
| Generating test code | Low | Easy | Yes | Individual | Use freely, run the tests |
| Summarising a research paper | Medium | Medium | Yes | Individual | Use as starting point, verify key claims |
| Generating production code | Medium | Easy | Yes | Varies | Use to accelerate, review thoroughly |
| Recommending products to customers | Low | Hard | Yes | Systematic | Deploy with monitoring and feedback loops |
| Screening CVs for hiring | High | Hard | Partially | Systematic | Use for surfacing only, human decides |
| Credit scoring for loans | High | Hard | Partially | Systematic | Rigorous audit, bias testing, human override |
| Triaging medical images | High | Hard | No | Systematic | AI flags, clinician decides. Never autonomous |
| Autonomous vehicle decisions | Critical | Impossible | No | Systematic | Extreme testing, redundancy, regulatory oversight |
Key principle. As you move down this table — higher stakes, harder verification, less reversibility, greater scale — the appropriate trust posture shifts from "use freely" to "AI informs, humans decide" to "deploy only with extraordinary safeguards." There is no row where blind trust is appropriate.
The graduated handover
Another way to think about the trust spectrum: how much decision authority are you handing to the system?
- Spam filtering and routing — low stakes, easy to override. Full automation is appropriate.
- Drafting and analysis support — useful if you still do the thinking. AI accelerates; human evaluates.
- Eligibility screening and shortlisting — starts affecting opportunity and fairness. Human oversight is structurally necessary, not optional.
- Hiring, credit, and underwriting decisions — a bad decision can change a life path. AI may surface and rank, but humans must decide.
- Medical triage, sentencing, safety-critical systems — deep oversight, explanation, and appeal required. Autonomy here demands extraordinary safeguards.
The further down this list you go, the more you should demand explainability, the right to appeal, and a named human accountable for the outcome.
The same model, different moral stakes
The same underlying technology can carry entirely different moral weight depending on context. Consider the contrast between AI in finance and AI in healthcare or public decisions:
| Finance | Healthcare / public decisions | |
|---|---|---|
| Cost of error | Wrong output can lose money | Wrong output can harm a life or alter life chances |
| Feedback speed | Often faster and clearer (P&L, market prices) | May be slow, partial, or ambiguous |
| Error tolerance | Some error may be tolerated if returns are strong | Explainability, appeals, and oversight matter more |
| Human review | Often easier to retain in the loop | Human review cannot be a cosmetic afterthought |
This distinction is critical for anyone deploying AI across multiple domains. The trust posture that is appropriate in a trading context — where feedback is fast, errors are financially bounded, and positions can be unwound — is wholly inappropriate in a medical or criminal justice context, where feedback is slow, errors affect individuals' lives, and reversal may be impossible.
Worked Examples
Example 1: Using AI to draft a quarterly business review
Stakes: Medium. An inaccurate claim in an internal document could mislead leadership, but the consequences are recoverable.
Verifiability: Medium. You can check figures against source data, but subtle framing errors are harder to catch.
Reversibility: High. You can correct and redistribute.
Scale: Limited. Internal audience.
Appropriate trust: Use AI to produce the first draft. Verify all data points against source systems. Read the full draft critically, paying particular attention to causal claims and characterisations the AI may have inferred rather than sourced. Do not send without a full read-through.
Example 2: Using AI to screen job applicants
Stakes: High. Wrongful rejection can damage individuals' livelihoods and expose the organisation to legal risk.
Verifiability: Hard. You cannot easily verify that the system's ranking criteria are fair without structured auditing.
Reversibility: Partial. You can re-review rejected candidates, but many will have moved on.
Scale: Systematic. Applied to every applicant.
Appropriate trust: Use AI to surface candidates for human review, not to make rejection decisions. Audit the system regularly for demographic bias. Ensure rejected candidates have a path to human review. Never use AI as the sole decision-maker for hiring.
Example 3: Using AI for commodity price forecasting
Stakes: High. Inaccurate forecasts can lead to significant financial losses or mispriced contracts.
Verifiability: Delayed but possible. Forecasts can be evaluated against realised prices, but only after the fact.
Reversibility: Partial. Positions can be unwound, but often at a cost.
Scale: Varies. Individual trades to portfolio-wide hedging strategies.
Appropriate trust: Use AI forecasts as one input among several. Backtest rigorously on out-of-sample data. Combine with fundamental analysis and domain expertise. Set position limits that assume the model will sometimes be wrong. Monitor for regime changes that might invalidate the model's training assumptions.
Applying It
Four questions for daily use
Most routine AI interactions do not require a formal assessment. The framework builds operational intuition. Four questions are sufficient:
- What happens if this is wrong? (Stakes)
- Can I tell if it is wrong? (Verifiability)
- Can I fix it if it is wrong? (Reversibility)
- How many people does this affect? (Scale)
If the answers are "not much," "yes," "easily," and "just me" — use the AI freely. As any of those answers shift toward the uncomfortable end, increase your oversight proportionally.
For organisational decisions
When deploying AI in a product, using it in a hiring pipeline, or automating financial decisions, the framework should be applied more formally. Document the assessment. Revisit it when the system changes or when the context shifts. Make someone accountable for monitoring the dimensions over time.
The one-sentence version. Trust AI in proportion to how cheaply you can recover from its mistakes, and inversely to how many people those mistakes would affect.
Related Reading
- A Sceptic's Guide to AI — the pillar page introducing the Trust Calculus and the broader framework
- AI Bias Examples: How Useful Systems Can Still Be Unfair — why bias matters for trust decisions
- AI Theatre vs Real AI — how to tell whether an AI system delivers genuine capability
- AI Governance in Practice — what happens when AI enters organisational decision-making
Need help evaluating AI systems for your organisation? I advise on applied AI strategy and risk assessment. Get in touch.
Written by Dr Tristan Fletcher.