A Sceptic's Guide to AI
Real-world systems, academic questions, human consequences
A Sceptic's Guide to AI

I have spent twenty years building AI systems — from academic research in machine learning at UCL, through quantitative trading at Aspect Capital and UBS, to founding ChAI, which uses AI to forecast commodity prices. I started fascinated by the power of these systems. I am now more impressed by what they can do, and considerably less gullible about what they cannot. AI is powerful enough to take seriously, and fallible enough to treat sceptically.
This guide is drawn from that experience and from a presentation I give to organisations navigating AI adoption. The core argument: the right level of trust in any AI system depends on what is at stake and whether you can check the output. The hardest problems with AI are not technical — they are human. Governance, accountability, and the discipline to maintain judgement when a system makes it easy not to.
Contents
What AI Actually Is

AI is a tool shaped by its objective, not by wisdom. Machine learning systems find regularities in data and exploit them to make predictions or generate outputs — at a scale and speed that humans cannot match. They are strong at narrow tasks with abundant examples. They are often better than humans at consistency and throughput. That is genuinely powerful.
What AI is not:
- Not general understanding — a model that produces fluent text about cardiac surgery does not understand hearts
- Not truth just because it sounds confident — fluency and correctness are unrelated properties
- Not neutral just because it is quantitative — every model inherits the assumptions in its training data
- Not a substitute for judgement — it is a tool that should inform judgement, not replace it
- Not reliable far outside its training conditions — distribution shift breaks models silently
The gap between "produces useful outputs" and "understands the domain" is where the most dangerous failures occur. A system that is right 95% of the time is adequate for spam filtering. It is not adequate for underwriting or triage — not because 95% is a bad number, but because the 5% failure mode is invisible to anyone who assumes the system understands what it is doing.
Why Practical Scepticism Matters
Scepticism has an undeserved reputation as negativity. In practice, scepticism about AI is the same as scepticism about any tool: it means asking whether it works before betting on it, and understanding how it fails before relying on it.
The alternative — uncritical adoption — creates real problems. Organisations deploy AI systems without understanding their limitations. Users trust outputs they have no way of verifying. Decision-makers defer to algorithms they could not explain. The result is not efficiency. It is a new kind of fragility, where errors are automated, scaled, and difficult to detect.
Practical scepticism does not mean refusing to use AI. It means:
- Asking what the system was trained on and whether that matches your use case
- Checking whether the output can be verified independently
- Understanding what happens when the system is wrong
- Keeping humans in the loop where the consequences of errors are serious
None of this is anti-technology. It is operational discipline applied to a new class of tools.
AI already shapes your operating environment
This is not a future concern. AI systems already determine what information reaches you, how you are assessed, what your organisation produces, and how attention is allocated across your business and your market.
Search ranking, feed algorithms, CV screening, credit scoring, fraud detection, drafting tools, coding assistants — these are not peripheral systems. They sit in the critical path of decisions that affect revenue, risk, reputation, and resource allocation.
Real AI vs AI Theatre

Not everything branded as AI delivers genuine AI capability. A significant portion of what the market calls "AI-powered" falls into one of three categories:
Real capability. Systems where machine learning genuinely improves outcomes — language translation, protein structure prediction, commodity price forecasting, medical image analysis. These systems do things that would be impractical or impossible without the underlying technology.
AI theatre. Systems that use AI branding without delivering AI value. A chatbot bolted onto a FAQ page. A "smart" thermostat running the same schedule logic it always did. A product that rebrands if-then rules as "machine learning." The AI label adds cost and complexity without improving the outcome.
Good technology in the wrong context. Systems where the AI component works but does not solve the actual problem. A sophisticated sentiment analysis engine that tells you customers are unhappy — something you could learn by reading five support tickets. Genuine capability, misapplied.
The ability to distinguish between these categories is one of the most practically valuable skills in the current technology landscape. For a deeper treatment and a checklist you can apply, see AI Theatre vs Real AI: How to Tell the Difference.
The AI Trust Calculus
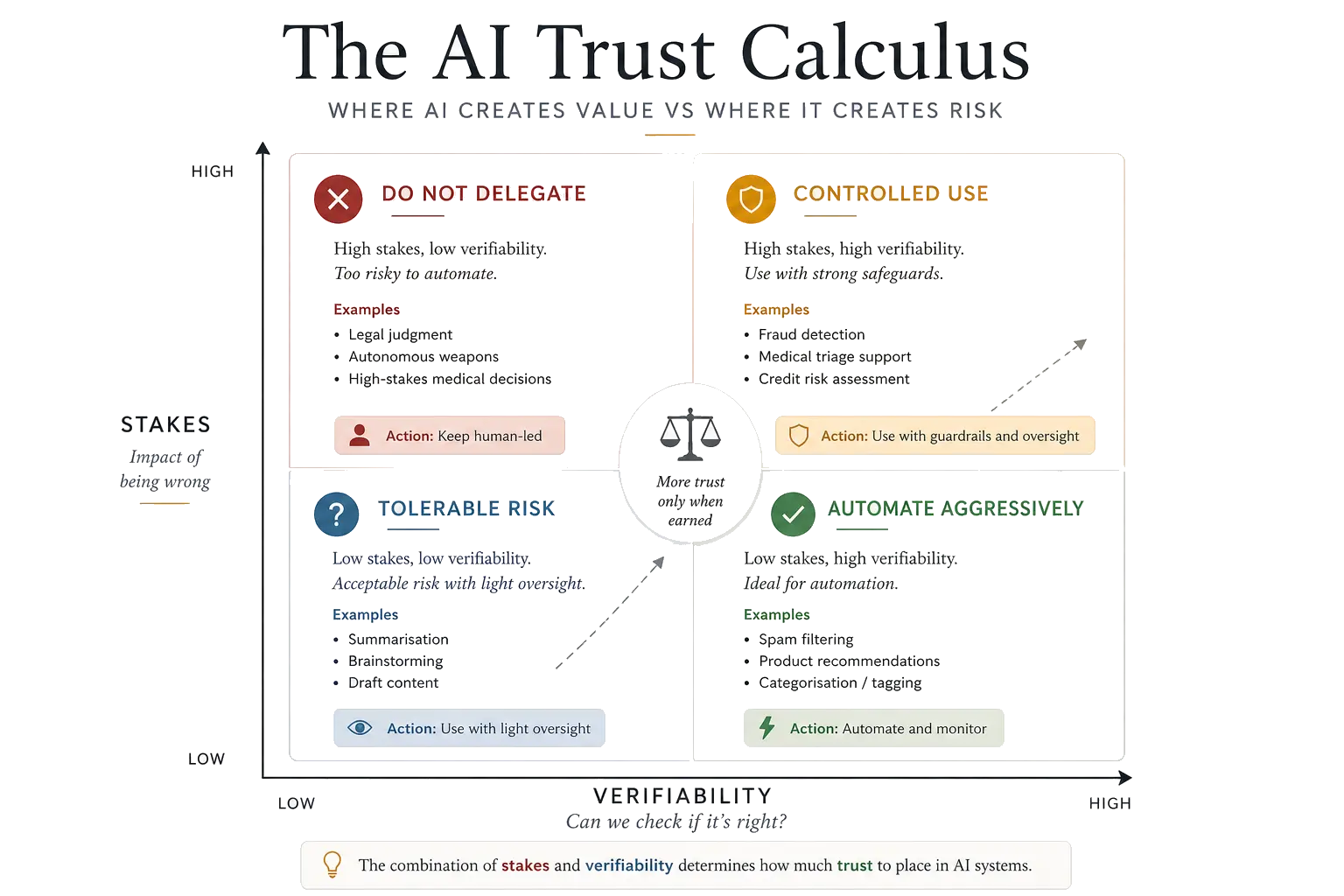
The central framework of this guide is what I call the AI Trust Calculus: a structured way to decide how much trust to place in any AI system for a given task.
It rests on two dimensions:
- Stakes — what happens if the system is wrong? An incorrect spam filter wastes a few seconds of your time. An incorrect risk assessment can lose millions or deny someone a livelihood. The consequences of error should determine the rigour of your oversight.
- Verifiability — can you check whether the output is correct? A code suggestion is verifiable: you can read it, test it, run it. A legal summary of an unfamiliar jurisdiction is much harder to verify without independent expertise.
| Easy to verify | Hard to verify | |
|---|---|---|
| Low stakes | Trust freely. Automate where possible. Spam filtering, email drafts, data formatting. | Use with awareness. Spot-check periodically. Research summaries, demand forecasts, translation. |
| High stakes | Trust but verify. Confirm outputs before acting. Code generation, financial modelling, engineering calculations. | Do not delegate. AI informs; humans decide. Medical diagnoses, hiring, credit decisions, safety-critical systems. |
This is deliberately simple. The power is in applying it consistently. Every time you encounter an AI system — whether you are building it, buying it, or using it — ask two questions: What happens if this is wrong? and Can I tell if it is wrong? The intersection of those answers tells you how much trust is appropriate.
For a detailed version of this framework with additional dimensions (reversibility, scale, domain stability) and worked examples, see When Should You Trust AI? A Practical Framework.
Where AI Fails

Bias and unfairness
AI systems learn from historical data, and historical data reflects historical decisions — including biased ones. A hiring model trained on a decade of CVs from a company that predominantly hired men will learn to prefer male candidates. A lending model trained on data from a period of discriminatory lending will perpetuate those patterns.
The nuance that often gets lost: humans are frequently more biased than algorithms. A well-audited model can be more consistent and less prejudiced than an overworked human decision-maker at 4pm on a Friday. But algorithmic bias scales in ways that human bias does not. A biased hiring manager affects dozens of candidates. A biased algorithm can affect millions.
The practical response is not to avoid AI in consequential decisions, but to audit rigorously, test for disparate impact, and maintain human oversight where it matters. For real-world examples and a more detailed treatment, see AI Bias Examples: How Useful Systems Can Still Be Unfair.
Manipulation and dependency
Systems optimised for engagement learn to manipulate. This is not a bug — it is the direct consequence of the objective function. A recommendation algorithm told to maximise time-on-site will serve content that provokes outrage, because outrage is engaging. A news feed optimised for clicks will surface conflict over consensus, sensationalism over substance.
The manipulation problem extends to individual interactions with AI assistants. Systems designed to be helpful and agreeable can reinforce existing beliefs rather than challenge them.
The risk is not that AI will overpower human agency through superior intelligence, but that it will erode it through persistent agreeableness.
Over-trust and automation complacency
The better an AI system works most of the time, the more dangerous it becomes when it fails. This is automation complacency — the well-documented tendency for humans to reduce their vigilance when a system is usually right. Pilots who rely on autopilot become slower to detect failures. Radiologists who use AI screening tools spend less time on cases the AI flags as normal.
The irony is precise: the more reliable we make AI systems, the less prepared we are for their failures. The practical response is to design for failure, not just for success — to build systems and processes that assume the AI will sometimes be wrong and ensure that humans are equipped to catch it when it is.
Power concentration and accountability
Advanced AI systems require enormous datasets, vast compute, and specialised talent. This concentrates capability in a small number of well-resourced organisations — the entities best positioned to build and deploy AI, and the entities with the least incentive to constrain it.
Three questions expose the structural problem:
- Who controls the tools? A few organisations shape the models, infrastructure, and application ecosystems that everyone else depends on.
- Who sets the defaults? They determine what is visible, what is restricted, and which behaviours are rewarded by the system.
- Whose values get embedded? Every system carries assumptions about risk, fairness, and safety. These choices are never purely technical.
And the question that matters most in practice: if the system gets it wrong, who explains the decision — and who has the power to fix it?
Responsibility is fragmented across engineers, product managers, deploying organisations, and end users. When automated systems fail, the trail of accountability is often impossible to reconstruct.
Using AI Well

The goal is not to avoid AI. It is to use it to accelerate work, not replace thinking.
Check outputs, don't trust them
Treat confident output as something to verify, not something to accept. The moment you stop evaluating — the moment you accept an AI output because the AI produced it rather than because you assessed it — you have stopped using a tool and started following an oracle.
Apply the Trust Calculus
Before relying on any AI output, ask: what are the stakes, and can I verify this? Let the answer determine your level of oversight.
Complement judgement, don't replace it
If you use AI to generate analyses, you still need to understand the domain. If you use AI to draft strategy documents, you still need to know what you want to say. The moment AI becomes a substitute for competence rather than a complement to it, you have created a dependency you cannot manage.
Demand transparency
If a system cannot explain its outputs, that does not mean the outputs are wrong — but it does mean you cannot audit them. In high-stakes contexts, unexplainable outputs are unacceptable regardless of their accuracy.
Never let convenience become dependence
The greatest risk with AI is not spectacular failure. It is that it will work well enough, often enough, that we stop thinking critically about it. Scepticism is not a phase to pass through on the way to adoption. It is a permanent operational posture.
Key takeaways:
- AI is a tool shaped by its objective, not by wisdom — powerful but not understanding
- Scepticism should rise as the cost of error increases and the ease of oversight falls
- Not everything called AI deserves the name — and not every real AI use case is a sensible one
- Decisions wrapped in math look objective but can quietly scale old prejudices
- If the system gets it wrong, ask: who explains the decision, and who has the power to fix it?
- Use AI — but do not hand over your judgement
Common Questions

Is this an anti-AI argument?
No. The argument is not that AI is useless or dangerous by default. It is that AI should be judged by the task, the evidence, the stakes, and whether its outputs can be checked. Practical scepticism makes AI more useful because it separates real capability from theatre.
Where does AI work best?
AI works best where the task is low enough risk, the output is easy to verify, and mistakes can be corrected quickly. That is why classification, search, recommendations, drafting, summarisation, forecasting support, and anomaly detection can be valuable when used with the right checks.
Where should AI be treated with caution?
AI needs much stronger oversight when the stakes are high or the answer cannot be independently verified. Legal judgement, medical diagnosis, welfare decisions, policing, hiring, and other consequential decisions should not be delegated to opaque systems without clear accountability.
What is AI theatre?
AI theatre is the appearance of intelligence without meaningful capability, accountability, or evidence. It often involves adding a chatbot, automation layer, or "AI-powered" label to a process without changing the underlying decision quality. For a detailed treatment, see AI Theatre vs Real AI.
What is the AI Trust Calculus?
The AI Trust Calculus is a simple way to decide how much confidence to place in an AI system. The two questions are: how serious would an error be, and how easily can the output be checked? Low-stakes, high-verifiability tasks are the safest place to use AI aggressively; high-stakes, low-verifiability tasks require human control. For the full framework, see When Should You Trust AI?
What is the right role for humans?
Humans should not merely rubber-stamp AI outputs. Their role is to define the problem, understand the context, challenge the output, check the evidence, and remain accountable for consequential decisions.
Further Reading
- When Should You Trust AI? A Practical Framework — the full AI Trust Calculus with worked examples
- AI Bias Examples: How Useful Systems Can Still Be Unfair — real-world bias cases and what they teach us
- AI Theatre vs Real AI: How to Tell the Difference — a checklist for separating substance from spin
- AI Governance in Practice — what changes when AI systems begin shaping decisions and authority inside organisations
I advise organisations on applied AI strategy and speak on the practical challenges of AI adoption. If your team is navigating these questions, get in touch.
Written by Dr Tristan Fletcher.