Support Vector Machines Explained
A Step-by-Step Introduction to Support Vector Machines
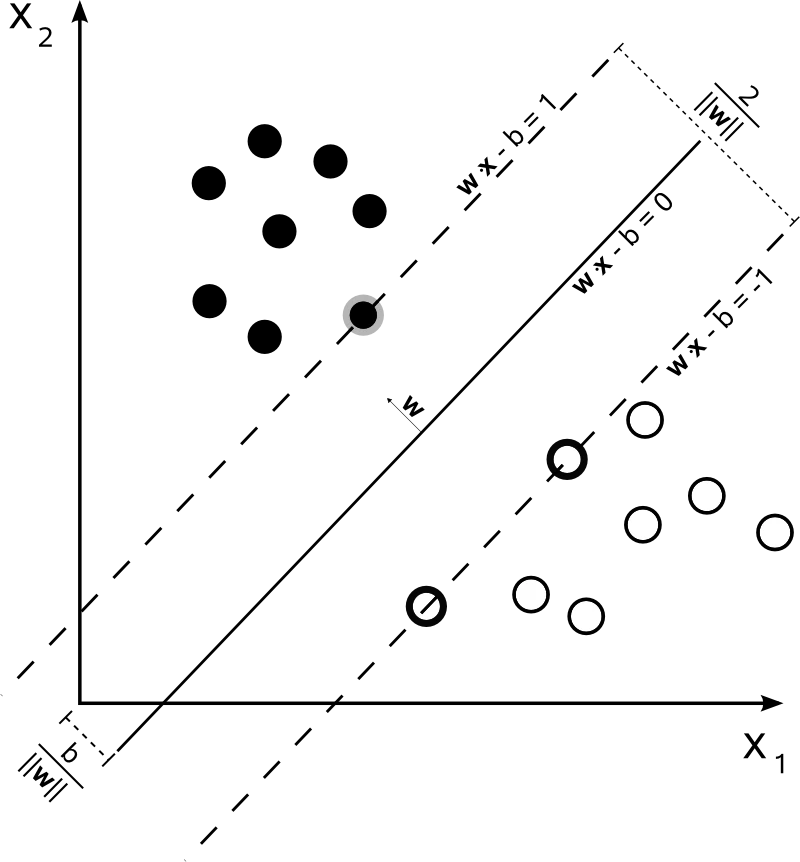
This tutorial paper has been written to make Support Vector Machines (SVMs) as simple to understand as possible for those with minimal experience of Machine Learning. It assumes basic mathematical knowledge in areas such as calculus, vector geometry and Lagrange multipliers.
The document is split into Theory and Application sections so that it is clear, after the maths has been dealt with, how to actually apply the SVM for the different forms of problem that each section is centred on.
What Is a Support Vector Machine?
A Support Vector Machine (SVM) is a supervised learning algorithm that finds the optimal hyperplane separating two classes of data by maximising the margin — the distance between the decision boundary and the nearest training points (the "support vectors"). First introduced by Vladimir Vapnik and colleagues in the 1990s, SVMs remain one of the most widely used classifiers in machine learning, valued for their strong theoretical guarantees and effectiveness on small-to-medium datasets.
What makes SVMs particularly powerful is the kernel trick: by replacing dot products with kernel functions, an SVM can learn non-linear decision boundaries without explicitly computing the coordinates in a high-dimensional feature space. Common kernels include the polynomial kernel, radial basis function (RBF or Gaussian) kernel, and sigmoid kernel. The choice of kernel and its parameters has a significant impact on model performance.
What the Tutorial Covers
- Hard-margin and soft-margin classification
- The primal and dual formulations
- Kernel functions and the kernel trick
- Multi-class SVMs
- SVM regression
- Practical guidance on applying SVMs to real data
From Theory to Practice
The tutorial is split into Theory and Application sections. The theory sections derive the SVM formulation from the hard-margin case through to the soft-margin classifier (which tolerates misclassifications via slack variables) and the dual form (which enables the use of kernels). The application sections show how to use SVMs for multi-class classification, regression (SVR — Support Vector Regression), and practical data preparation.
For a Bayesian alternative to SVMs that produces sparser models and probabilistic outputs, see the companion tutorial on Relevance Vector Machines.
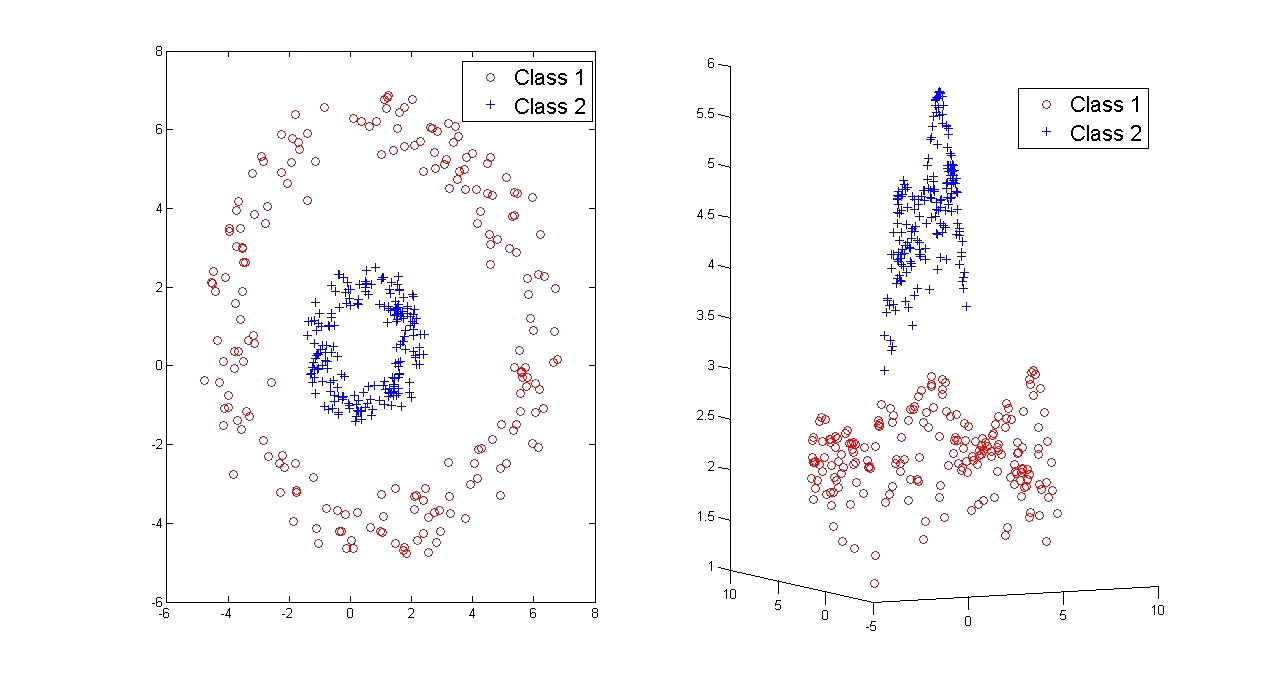
Support Vector Machines in Practice
SVMs have been applied successfully across a wide range of domains. In text classification, SVMs remain a strong baseline for spam filtering, sentiment analysis and document categorisation — their effectiveness in high-dimensional, sparse feature spaces makes them a natural fit. In bioinformatics, SVMs are used for protein classification, gene expression analysis and cancer diagnosis from microarray data. In computer vision, SVMs powered early object detection systems (notably the HOG+SVM pedestrian detector) and continue to be used where training data is limited.
In quantitative finance, SVMs have been applied to predict market direction, classify credit risk and detect fraud. The author's own research has used SVMs with financially motivated kernel functions to predict high-frequency currency movements — see the publications page for details. For problems where probabilistic outputs and sparser models are preferred, consider the Bayesian alternative: Relevance Vector Machines.
Download the full tutorial (PDF)
Frequently Asked Questions about Support Vector Machines
What is a support vector machine?
A support vector machine (SVM) is a supervised machine learning algorithm that finds the optimal hyperplane separating two classes of data by maximising the margin — the distance between the decision boundary and the nearest training points. These nearest points are called "support vectors" because they are the only data points that define the position and orientation of the hyperplane.
What is the kernel trick in SVMs?
The kernel trick allows SVMs to learn non-linear decision boundaries without explicitly computing coordinates in a high-dimensional feature space. By replacing dot products with a kernel function (such as the Gaussian RBF or polynomial kernel), the SVM implicitly operates in a much higher-dimensional space while only computing pairwise similarities in the original space. This makes non-linear classification computationally tractable.
What is the difference between hard-margin and soft-margin SVMs?
A hard-margin SVM requires that all training points are correctly classified with no points inside the margin. This only works when the data is perfectly linearly separable. A soft-margin SVM introduces slack variables that allow some points to violate the margin or be misclassified, controlled by a regularisation parameter C. Soft-margin SVMs are far more practical since real-world data is rarely perfectly separable.
When should I use support vector machines?
SVMs work well on small-to-medium sized datasets (up to tens of thousands of samples), in high-dimensional feature spaces, and when the number of features exceeds the number of samples. They are less suited to very large datasets where training time scales poorly, or where probabilistic outputs are required (consider Relevance Vector Machines for that). For tabular data, gradient-boosted trees often outperform SVMs; for image and text data at scale, deep learning is typically preferred.
How do support vector machines compare to neural networks?
SVMs have stronger theoretical guarantees (structural risk minimisation) and work well with limited training data, while neural networks excel when large amounts of data and compute are available. SVMs are convex optimisation problems with a unique global solution; neural networks have many local minima. For small datasets and structured features, SVMs often outperform neural networks. For unstructured data (images, text, audio) at scale, deep neural networks are generally superior.
Related Tutorials
- Relevance Vector Machines Explained — how sparse Bayesian learning with relevance vector machines compares with SVMs, with Python examples
- The Kalman Filter Explained — filtering and smoothing in Linear Dynamical Systems
Written by Dr Tristan Fletcher. Browse all ML tutorials.